Understanding AI Application Architecture

What does an AI application look like, really? After having built a few, it seems like a good time to break it down into its (many) parts—and explore the operational implications.
We’ve previously explored what’s the same (a lot) and what’s different (a lot) about AI applications. It’s easy enough to define an AI application as “an application that leverages AI, either predictive or generative.”
That’s true, but for the folks who must build, deploy, deliver, secure, and operate these new kinds of applications, what that does mean?
It means new moving parts, for one. And not just inferencing services. There are other new components that are becoming standard adds to the application architecture, like vector databases. It also means increased reliance on APIs.
It is also true that most of these components are containerized. When I set up a new AI application project, I fire up a container running PostgreSQL to use as a vector data store. That’s to support RAG (Retrieval Augmented Generation), which a significant percentage of AI applications are using according to multiple industry reports (this one from Databricks for example). That’s because I can augment a stock AI model using any data I like without having to fine-tune or train a model myself. For a significant number of use cases, that’s the best way to implement an AI application.
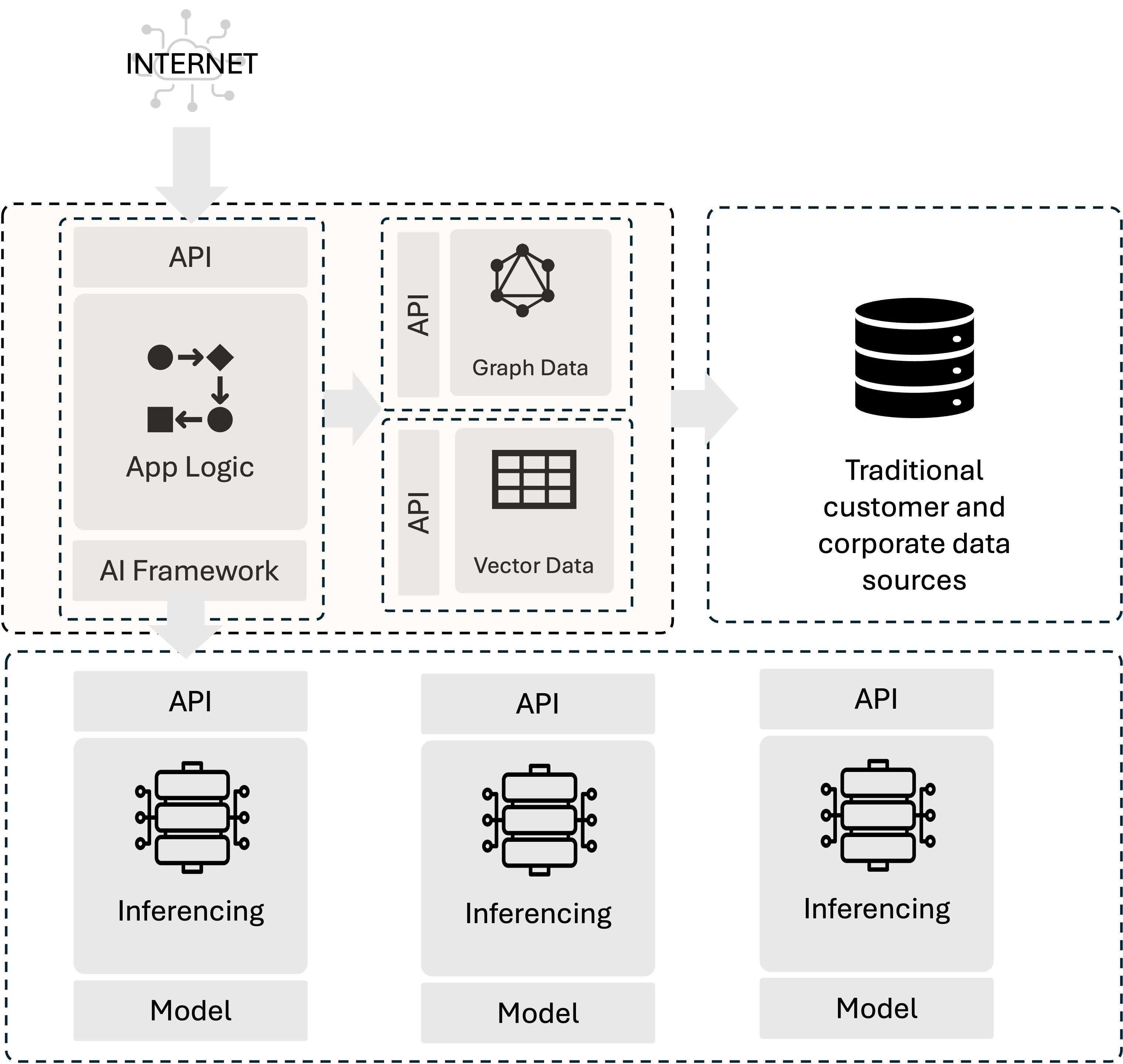
I may also fire up a knowledge graph, typically by running a containerized graph database like Neo4J. Graph databases are particularly useful when working with graph-affine data, like social networks, recommendation engine data, and fraud detection. It turns out they’re also useful in mitigating hallucinations related to policy generation, as we learned early in the year. Inclusion of a graph database can add a new protocol, GraphQL, to the list of ‘new things that need securing.’
Then I’m going to decide which inferencing service I want to use. I have options. I could use a cloud provider service or AI as a service (a la ChatGPT) or I could run a local service. For example, my latest tinkering has used Ollama and phi3 on my MacBook. In this case, I’m only running one copy of the inferencing server because, well, running multiple would consume more resources than I have. In production, of course, it’s likely there would be more instances to make sure it can support demand.
Because I’m going to use phi3, I choose phidata as my framework for accessing the inferencing service. I’ve also used langchain when taking advantage of AI as a service, a popular choice, and the good news is that from an operational perspective, the framework is not something that operates outside the core AI application itself.
Operational Impact of AI Applications
I haven’t even written a line of code yet and I’ve already got multiple components running, each accessed via API and running in their own containers. That’s why we start with the premise that an AI application is a modern application and brings with it all the same familiar challenges for delivery, security, and operation. It’s also why we believe deploying AI models will radically increase the number of APIs in need of delivery and security.
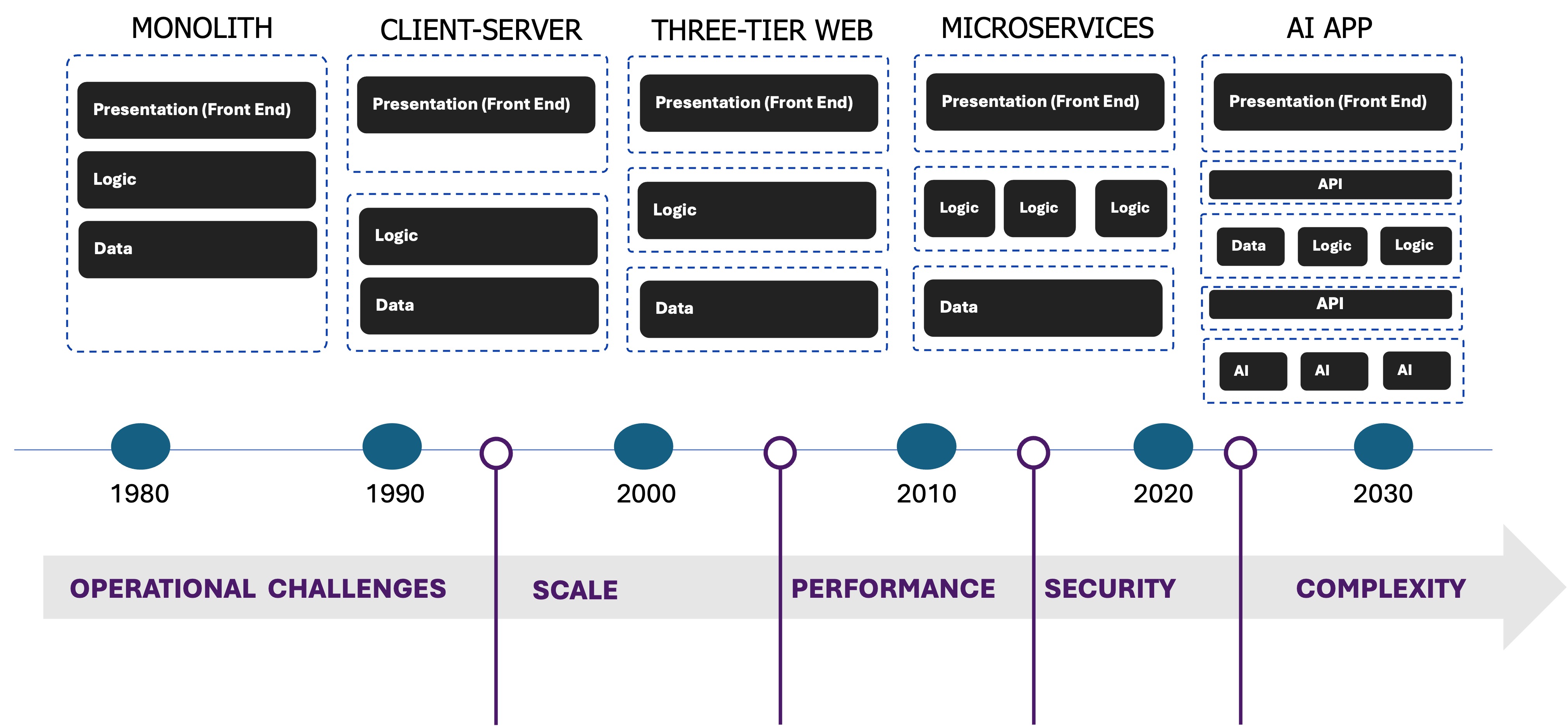
AI applications add another tier to an already complex environment which, of course, increases complexity. Which means AI application architecture is going to increase the load on all operations functions, from security to SRE to the network. Each of these components also has their own scaling profile; that is, some components will need to scale faster than others and how requests are distributed will vary simply because most of them are leveraging different APIs and, in some cases, protocols.
What’s more, AI application architecture is going to be highly variable internally. That is, the AI application I build is likely to exhibit different local traffic characteristics and needs than the AI application you build. And more heterogeneity naturally means greater complexity because it’s the opposite of standardization, which promotes homogeneity.
Standardization has been, for decades, the means through which enterprises accelerate delivery of new capabilities to the market and achieve greater operational efficiencies while freeing up the human resources needed to address the variability in AI application architectures.
This is why we see some shared services—particularly app and API security—shifting to the edge, a la security as a service. Such a set of shared services can not only better protect workloads across all environments (core, cloud, and edge) but provide a common set of services that can serve as a standard across AI applications.
Understanding the anatomy of AI applications will help determine not just the types of application delivery and security services you need—but where you need them.