Introduction
This article is the second in our Scraper series where we are deep diving into automated scraping. The previous article introduced the topic and covered the various sources of scraping traffic and their motivations. This article digs into ways to identify, detect and block/control scrapers. While there are many approaches to prevent or reduce unwanted scraping, they are not equally effective. This article will rate each of the potential approaches and provide the strengths and weaknesses of each.
How to Identify Scraping Traffic
The first step in the fight against scrapers is detection. There are several methods that can be used to identify scrapers. These methods differ depending on the category of scraper you are dealing with. In the previous article we identified seven different kinds of scrapers and described their different motivations and approaches. This difference in motivations and approaches results in different identification methods. Some scrapers, particularly benign search bots, are self-identifying, announcing their presence so that network and security teams will allow them to scrape content. However, there are also some other categories of scrapers like AI companies, competitors and malicious scrapers that go to great lengths to hide themselves and make their detection difficult. More sophisticated approaches would be needed to identify these kinds of scrapers.
Self-Identifying Scrapers
There are several scrapers that announce themselves and make it very easy to identify them. These bots typically identify themselves via the user agent string in the HTTP user agent header. Scrapers that self-identify typically have explicit permission to scrape or believe that they offer a valuable service to the targets of their scraping and hence will not be deterred from scraping. There are several categories of scrapers that fall into this category. Table 1 below highlights some examples of these.
| Category | Description | Entity Example |
| Search Engine Bots / Crawlers | Scrapers used to index the internet and power search engine results | Google Bing |
| Performance or Security Monitoring | Third-party services that use automation to test the performance, availability and security of Web, Mobile and API applications | Thousand Eyes Blue Triangle DynaTrace BugCrowd |
| Archiving | Services that catalog and archive web pages for posterity to keep an accurate record of what the internet looked like at points in time | The Internet Archive’s WayBack Machine |
These self-identifying scrapers tend to identify themselves in a number of different ways. The most common ways involve having their name somewhere in the HTTP headers for each request they send. These are commonly in the user agent header, though there are times when this can be in other headers.
The websites of many of these scrapers will provide detailed information on their scrapers, including how to identify them and at times how to opt out of being scraped. Often a list of IP addresses that are used by the scraper is also provided. It is important to review this documentation for any scrapers that might be of interest to you. Unscrupulous scrapers will commonly attempt to impersonate known self-identifying scrapers, which makes being able to distinguish between legitimate scrapers and imposters particularly important. Reading the documentation of the legitimate scrapers will allow you to be able to distinguish between them and the imposters. Many of these sites also provide tools to help you verify if a scraper you are seeing is the real one or an imposter. Below are some links to such documentation for some top self-identifying scrapers, as well as screenshots of those web pages.
Google Scraper Documentation
Link: https://developers.google.com/search/docs/crawling-indexing
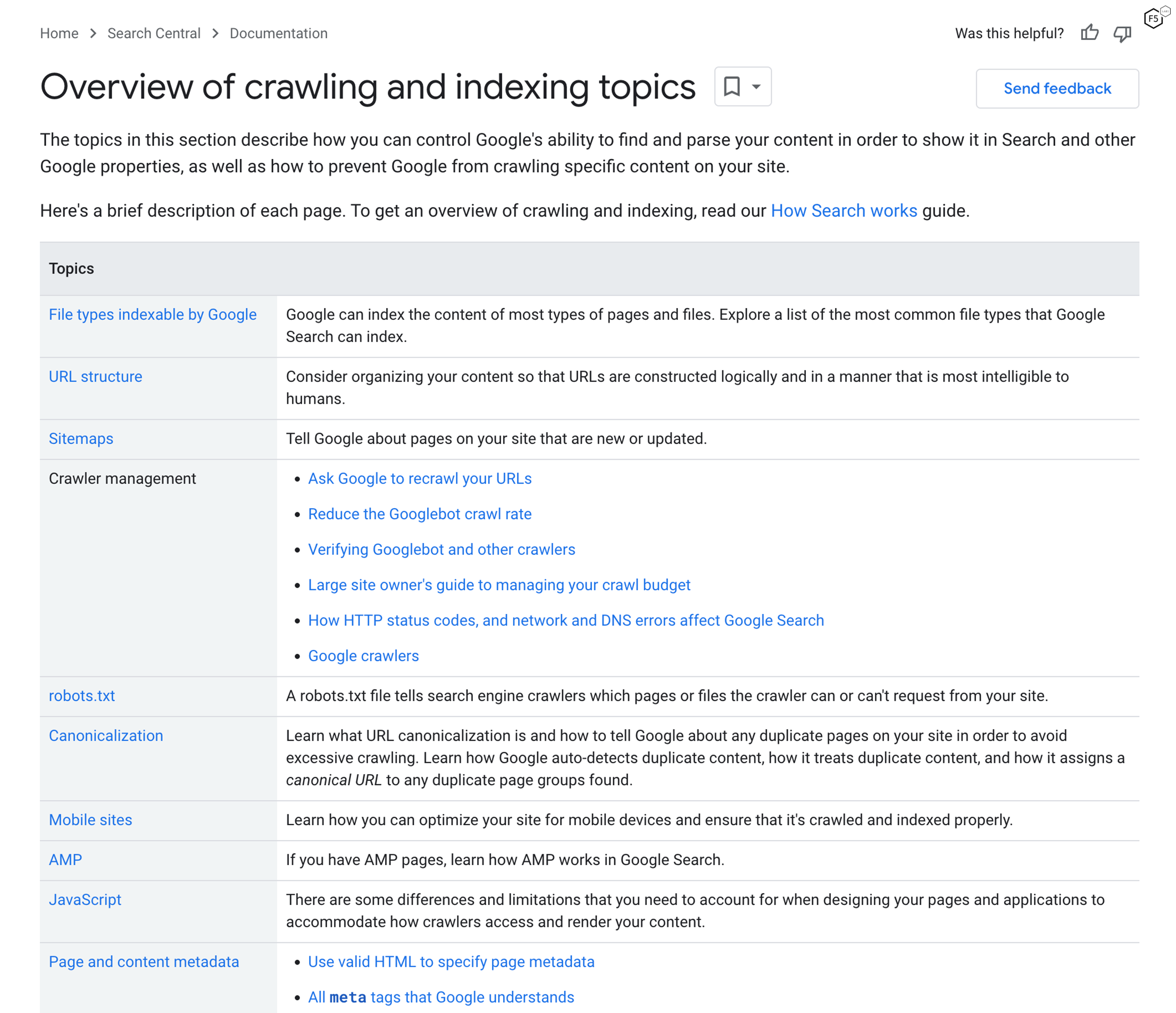
Figure 1: Screenshot of Google scraper bot documentation page
Bing Bot Scraper Documentation
Link: https://www.bing.com/webmasters/help/which-crawlers-does-bing-use-8c184ec0
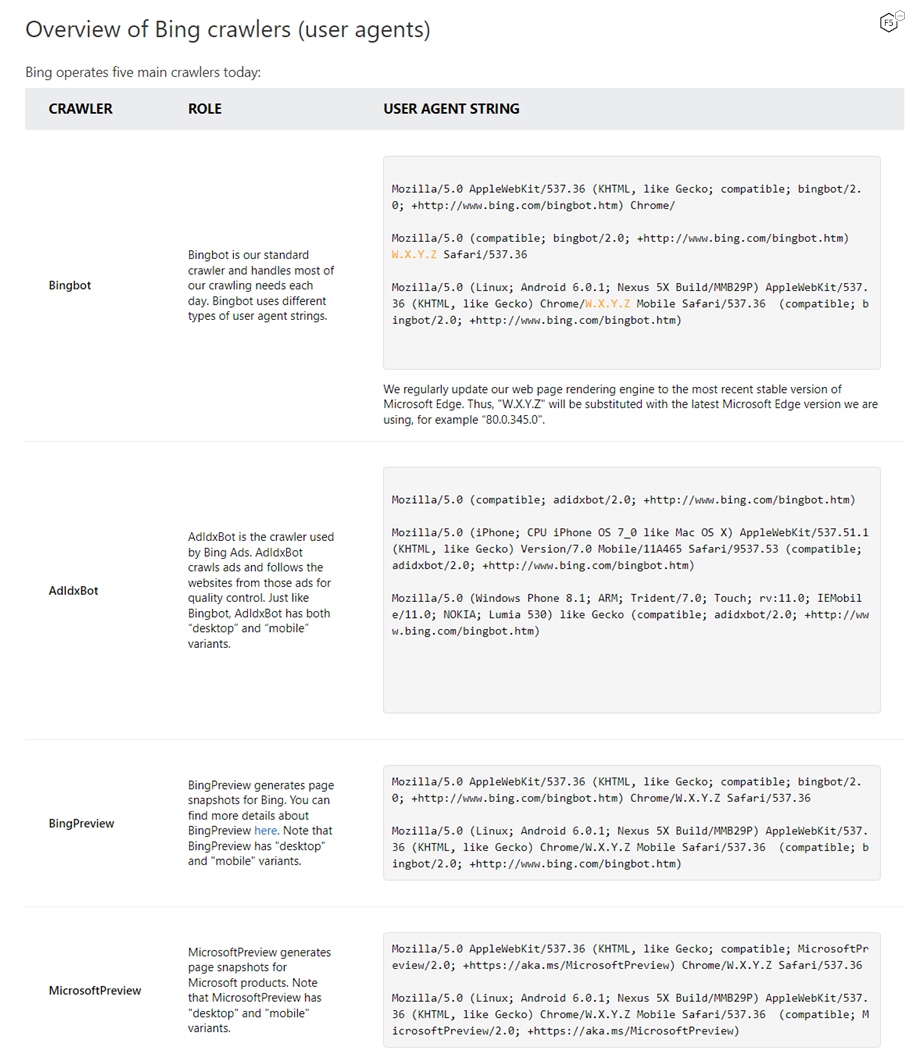
Figure 2: Screenshot of Bing scraper bot documentation page
OpenAI Scraper Documentation

Figure 3: Screenshot of Open AI’s scraper bots documentation page
Thousand Eyes Documentation

Figure 4: Screenshot of Thousand Eyes documentation User-agent based identification
Many scrapers identify themselves via the user agent string. A string is usually added to the user-agent string that contains
- The name of the company, service or tool that is doing the scraping
- A website address for the company, service or tool that is doing the scraping
- A contact email for the administrator of the entity doing the scraping
- Other text explaining what the scraper is doing or who they are
Because of this, one reliable way of trying to identify self-identifying scrapers is by doing a search in the user-agent field in your server logs. It is important to look for specific strings in the user agent string that will surface these scrapers. Common strings to look for are shown in Table 2 below.
| Self Identification method | Search String |
| Name of the tool or service | *Bot * or *bot* |
| Website address | *www* or *.com* |
| Contact Email | *@* |
Examples:
OpenAI searchbot user agent string :
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot
Bing search bot user agent string:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/
These scrapers have both the name of the tool or service, as well as the website in the user-agent string and can be identified using two of the methods highlighted in Table 2 above.
Impersonation
Because user agents are self-reported, they are easily spoofed. Any scraper can pretend to be a known entity like Google bot by simply presenting the Google bot user agent string. This impersonation is a tactic commonly used by unwanted scrapers as they know that most websites and APIs allow traffic from these entities because it boosts their visibility on the internet and allows them to acquire users. By presenting these impersonated user agent strings, scrapers are able to get unfettered access to the desired data. It is therefore a bad idea to allowlist scrapers simply on the basis of user agent strings; we have observed countless examples of fake bots impersonating large known scrapers like Google, Bing and Facebook.
As one example, Figure 5 below shows here the traffic overview of a fake Google scraper bot. This scraper was responsible for almost a hundred thousand requests per day against a large US hotel chain’s room search endpoints.
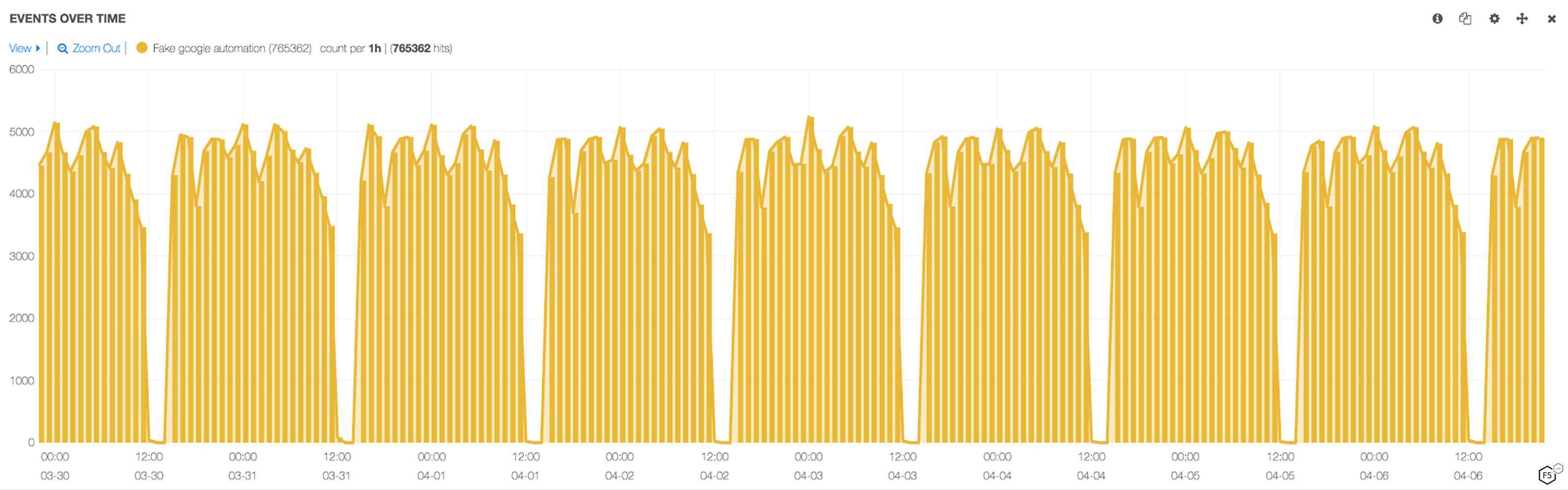
Figure 5: Traffic overview chart of fake Google bot scraper
The bot used the following user-agent string which is identical to the one used by the real Google bot.
Mozilla/5.0 (Windows NT 6.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) (765362)
However, this scraper used IP addresses from a Japanese ASN called KDDI Web Communications. This is not an ASN that Google uses. Google utilizes their own IP infrastructure and IPs that are registered to Google and its subsidiaries. These IPs are published on the Google website on the link shared above.
To prevent impersonation, it is important to have other ways of verifying the identity of a scraper. IP-based identification is another method that can be used.
IP-based Identification
Scrapers can identify themselves via their IP addresses. A whois lookup of the IP address can also reveal the company that owns the IP address and hence the identity of the organization behind the scraper. Some scrapers use IPs from their own registered ASNs which will reveal the name of the entity. Whois lookups for IPs that belong to cloud hosting or internet service providers may not reveal much information as to the identity of the actual entity behind the scraper. However, this method can be very useful in other instances. Whois lookups also reveal the geolocation information of an IP address. Though this information will not reveal a scraper's identity, getting many requests from unexpected locations may indicate automated scraping activity.
Reverse DNS lookups are another way to identify the entity behind a scraper. A reverse DNS lookup is defined as a query that uses the Domain Name System (DNS) to find the domain name associated with an IP address. The IP address of the scraper can be put into one of many free online reverse DNS lookup services and the domain associated with that IP address can be identified. This will provide information on the identity of the scraper.
Since IP address spoofing is non-trivial, identifying and allowlisting scrapers using IP addresses is more secure than simply using user agents.
Artificial Intelligence (AI) scrapers
Artificial intelligence companies need large amounts of data to train their models. They typically get this data by scraping the internet. Over the past year or two there has been an explosion in the volume of scraping on the internet that is driven by these companies. There is a lot of sensitivity around these companies scraping this data for free and then using that data to power for-profit AI models and services that at times compete against the companies that were unknowingly scraped and provided the training data. There are several lawsuits currently underway where AI companies are being sued for using such data to train their models. One prominent case is a class action lawsuit filed in California by 16 claimants against ChatGPT maker, OpenAI.1 The claimants claim that OpenAI’s scraping and use of their data to train its models infringed upon their copyrights.
Due to all this sensitivity around AI companies scraping data from the internet, a few things have happened.
- Growing scrutiny of these companies has forced them to start publishing details of their scraping activity and ways to both identify these AI scrapers as well as ways to opt out of your applications being scraped.
- AI companies have seen an increase in opt-outs from AI scraping resulting in them being unable to access the data needed to power their apps. Some less ethical AI companies have since set up alternative “dark scrapers” which do not self-identify, and instead secretly continue to scrape the data needed to power their AI services. A well-known example of this resulted from a Wired investigation into the AI company Perplexity, alleging the company was continuing to scrape data despite the site admins explicitly opting out of being scraped using the instructions provided by the AI company.2 This unauthorized scraping also utilized some IP addresses not listed on their published IP list at the time.
Businesses are looking for legal, regulatory and technological ways to identify and mitigate the activity of AI company scrapers on their Web, Mobile and API applications. For AI companies that are transparent about their activities and how to identify their scrapers and opt out, these are treated the same as self-identifying scrapers above. However for those “dark scrapers” that the less ethical AI companies are using to scrape despite attempts to opt-out, those will be treated the same as unidentified scrapers below. Details will be provided on how to identify these kinds of scrapers in that section below.
Unidentified Scrapers
Most scrapers do not identify themselves and do not ask for explicit permission to scrape desired data. As a result, application, network and security teams have no knowledge of their existence or activities on their Web, Mobile and API applications. If a scraper does not explicitly identify or announce itself, there are several methods that can be used to identify them. These methods can typically identify the existence of the scraper, but attribution – naming the entity behind the scraper – is a bit more difficult to do and at times is nearly impossible to do. However, we will highlight some techniques that we have used in the past to get to the identity of the organization or actors that are behind these scrapers.
Traffic Pattern Analysis
Traffic pattern analysis is a powerful tool that can be used to identify automated traffic of different kinds, including scrapers. Human traffic tends to follow a diurnal pattern where more transactions occur during the day, peaking around midday and then decreasing into the night. Figure 6 below gives an example of what diurnal human traffic patterns look like.
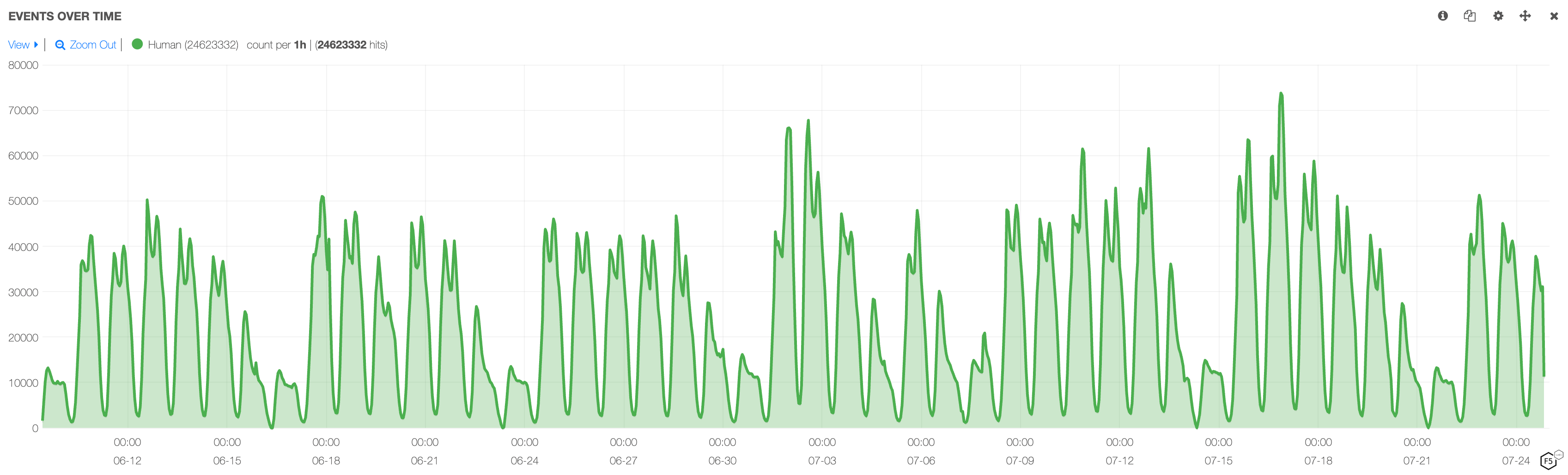
Figure 6: Example of human diurnal traffic pattern
Automated traffic does not typically follow a diurnal pattern which allows it to be identified. There are some exceptions to this rule, such as automated services initiated by a user in real-time, such as online insurance comparison scrapers. When a user goes to the website or app of these comparison services, they trigger the scraper to go out and gather insurance quotations from various providers. Because this automation makes requests in real time in response to a real user request, the resulting scraping activity will follow the same diurnal pattern as human traffic to the insurance comparison site or application. However, most unidentified scrapers operate differently.
In order to conduct traffic pattern analysis, it is important to slice and dice the traffic by different dimensions. You can analyze individual or groups of IPs, ASNs, user-agent strings, header orders, browser/device fingerprints, requested pages/endpoints etc. Looking at traffic on these dimensions may help surface unusual traffic patterns that would not show up when all traffic is viewed in aggregate due to relative traffic volumes. While analyzing traffic at this lower and more granular level, automated scraping traffic will typically follow some of the following traffic patterns.
Continuous Scraping Pattern
Some scrapers are continuously scraping data for a long period of time. This occurs either when the nature of the data desired requires continuous scraping, or rate limiting controls result in a scraper needing to run continuously for long periods of time to accumulate all the required data. Irrespective of the reason, scraper traffic typically tends to have this flat and boxy continuous traffic pattern. The volume of transactions does not decrease overnight or over weekends and public holidays in the same way human traffic would. Figure 7 below shows an example of a scraper that follows this traffic pattern.
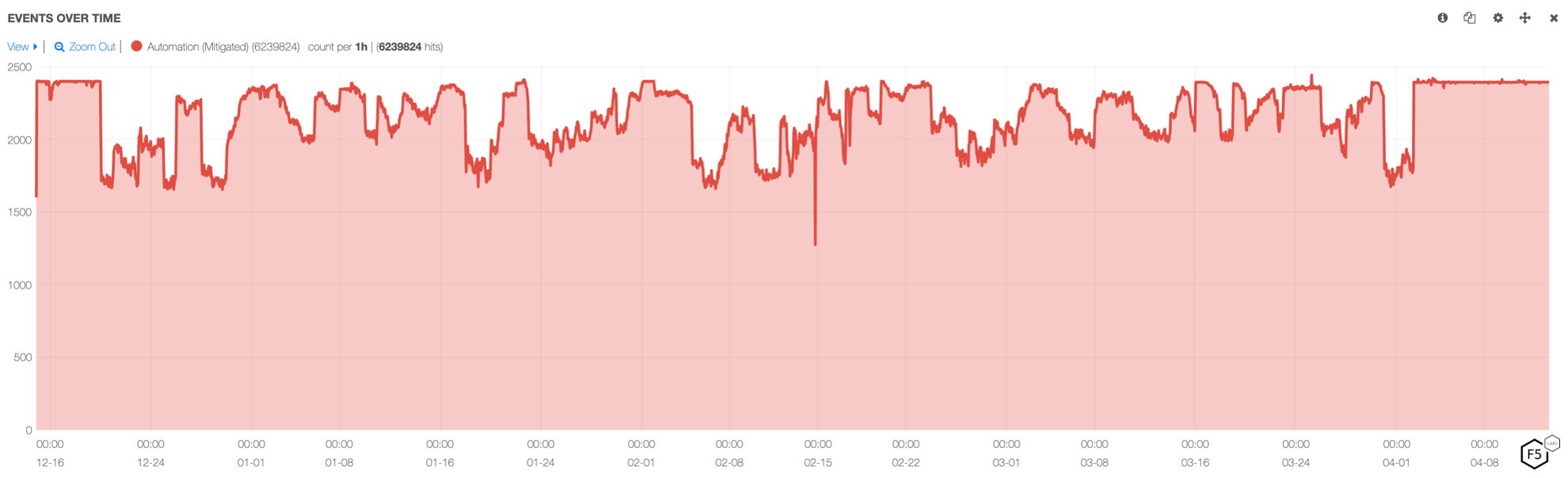
Figure 7: Example of continuous scraping pattern
Interval-based Scraping Pattern
This occurs when a scraper needs up-to-date data and must scrape the data based on some time interval which can be hourly, daily, weekly, monthly etc. This results in a traffic pattern illustrated in Figure 8 below.
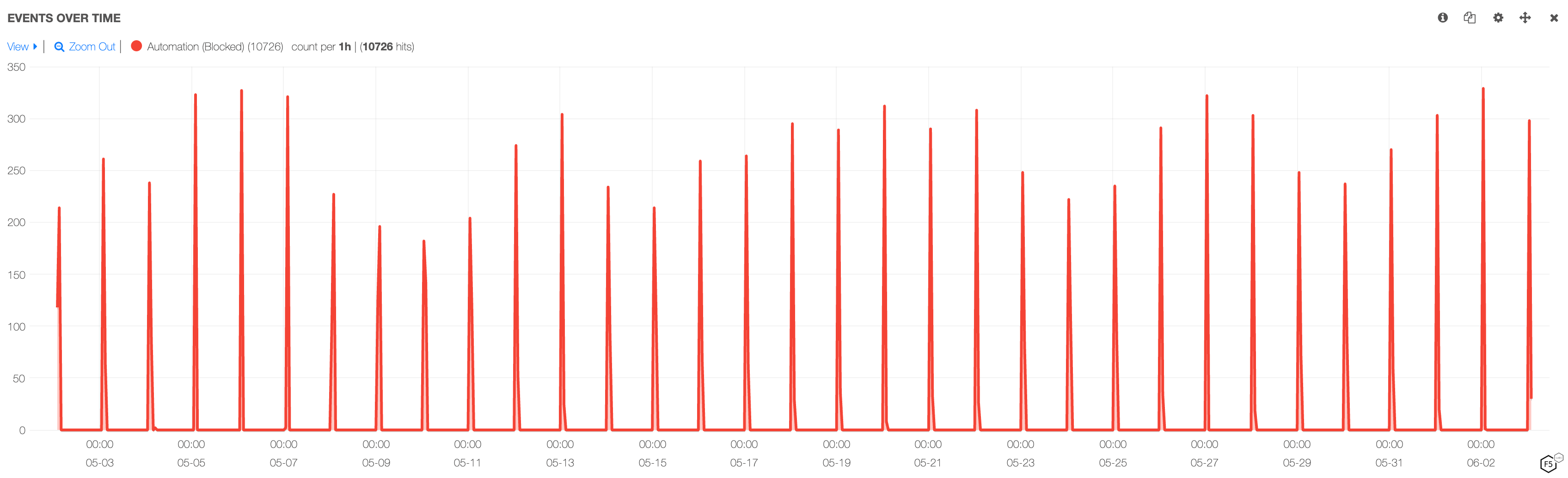
Figure 8: Example of interval based scraping
High Velocity Scraping Pattern
This traffic pattern is commonly observed with unsophisticated novice scrapers or when there is a small amount of data required that can be scraped in a very short period of time at high velocity without triggering rate limit controls. There are also instances where a large amount of data is needed for a very short period of time, such as in scraping the prices of financial assets at a particular time. This methodology results in large spikes of automated traffic that are very easy to identify and typically stick out like sore thumb. An example of such a high-velocity scraping pattern is shown in Figure 9 below.
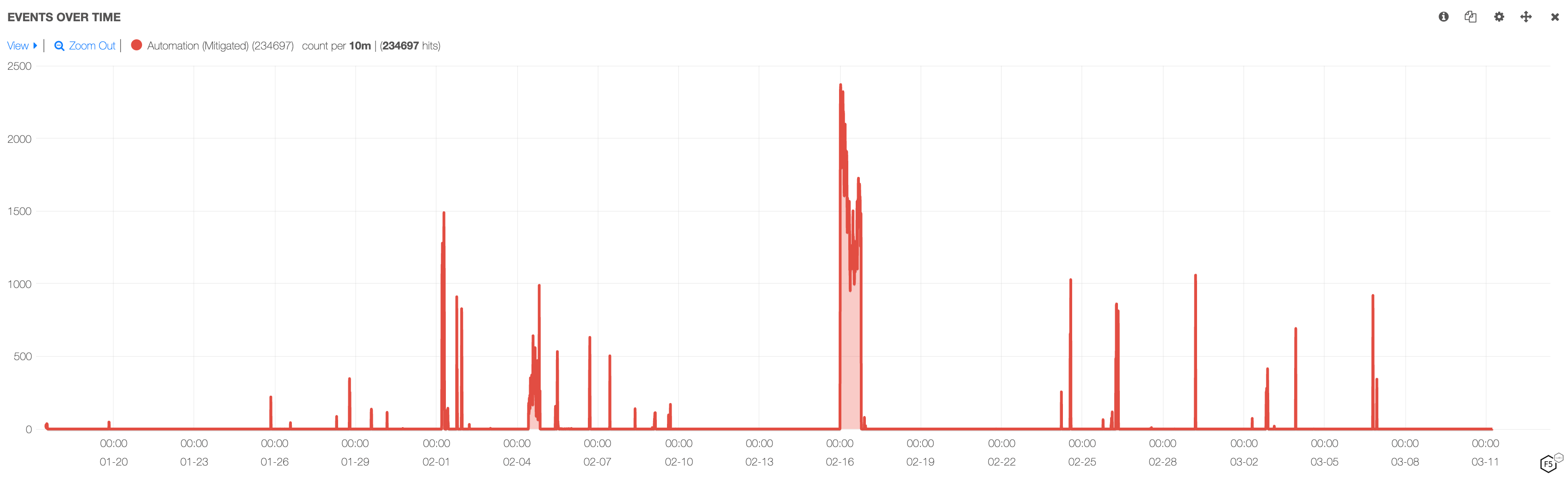
Figure 9: High-velocity scraping pattern
Requests for Obscure or Non-Existent Resources
Most websites have webpages and product/content pages that never receive traffic. Scrapers that are crawling an entire site will tend to request all available pages including these obscure pages as well. It is therefore easy to identify them by looking for entities that are requesting obscure or very low volume pages. Some scrapers, especially less sophisticated ones, are not customized for the entity they are scraping and request non-existent resources. An example is a flight scraper that pulls flight availability and pricing across different airlines. Such a scraper may request flights to and from destinations that the given airline does not fly to or from. These destinations are in the scraping tool because other airlines will have data for those destinations even though the current target might not. A real human user would not be able to request such destinations as the website or mobile app will not list such a destination, but a scraper can request any combination as it does not go through the target’s user interface but simply constructs the request manually and sends it directly to the airline’s origin servers. Figure 10 below shows an example of such a scraper that was scraping an airline’s flights and requesting flights to and from train stations.
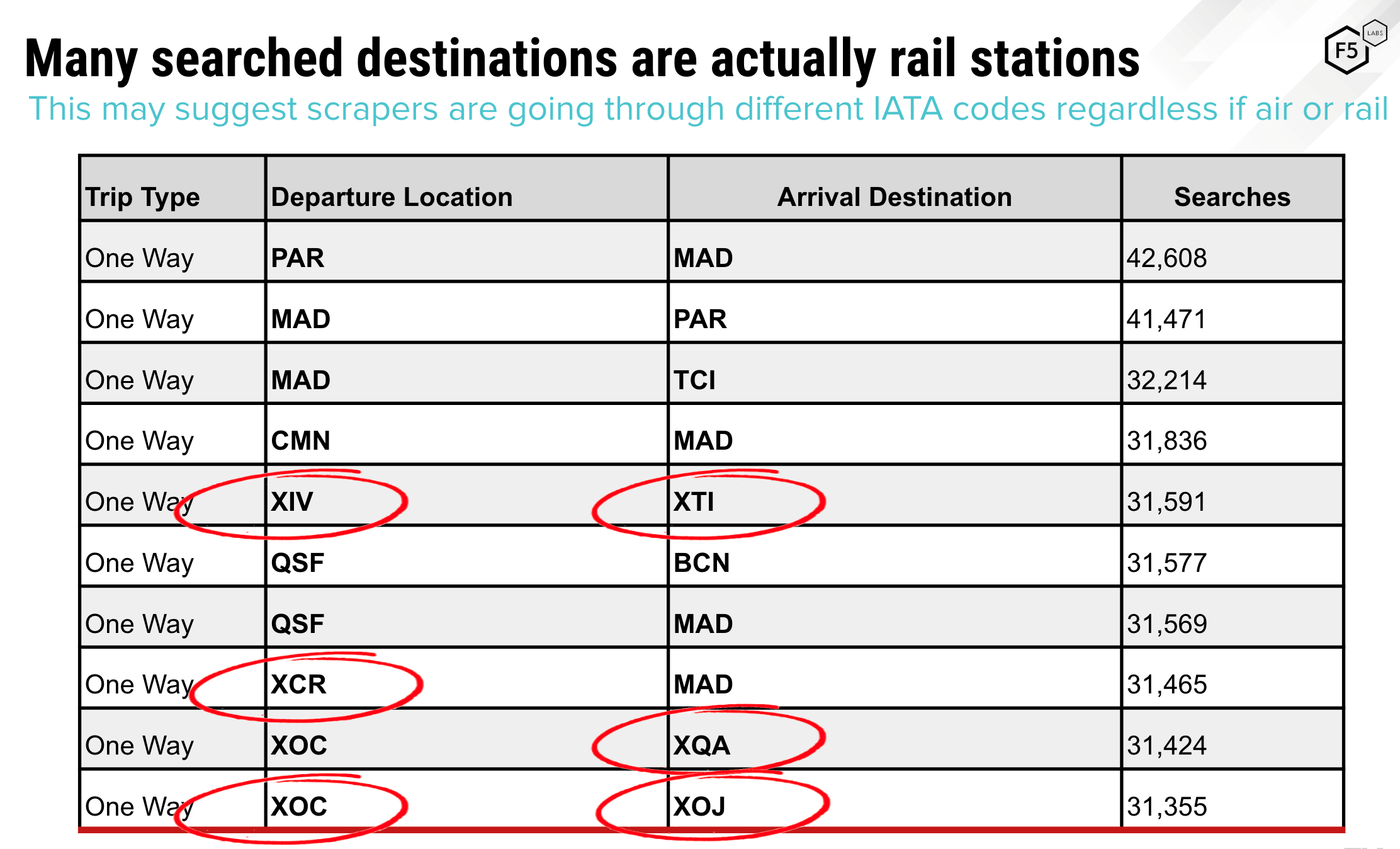
Figure 10: Flight scraper requesting nonexistent combinations of airports
IP Infrastructure Analysis, Use of Hosting Infra or Corporate IP Ranges (Geo Location Matching)
Scrapers have to distribute their traffic via proxy networks or bot nets so as to spread their traffic over a large number of IP addresses and avoid IP-based rate limits that are used to block unwanted scraping. Because of this, scrapers often do things that make it easier to identify them. These tactics include:
Round Robin IP or UA Usage
A scraper may distribute traffic equally among a given list of IP addresses. As it is highly unusual for any IP addresses to have the same volume of traffic, this serves as a sign of automated activity. There can be exceptions to this rule, such as NATed Mobile IPs that use load balancing to distribute traffic across available IPs.
Use of Hosting IPs
Getting a large number of IPs can be costly. Cloud hosting companies like Amazon Web Services and Microsoft Azure are the easiest and cheapest source of large numbers of IP addresses. However, we do not expect legitimate human users to access Web, Mobile and API applications using hosting IPs. A lot of scrapers use hosting IP infrastructure to distribute their traffic and use their compute and storage facilities to run the scraper and store the large amounts of resulting data. Looking for hosting IPs in traffic logs can help to identify unwanted unidentified scrapers.
Use of Low Reputation IPs
IP intelligence can be used to identify low reputation IP addresses that have been used in automated attacks. There are several third parties that provide IP intelligence services, and enterprises can also build their own database. Scrapers tend to rent proxy networks and botnets to distribute their traffic. These networks typically have been seen elsewhere on the internet engaged in bad activity. If you see searches on your Web, Mobile and API applications from these low reputation IP addresses, that might be indicative of unwanted scraping especially if the volume of transactions from those IPs is high.
Use of International IPs That Do Not Match Expected User Locations
The botnets and proxy networks that scrapers use tend to include IP addresses from all over the world. Some do exist that allow users to specify what geographic location they want IPs from, but these tend to cost more. Scrapers therefore tend to use IP addresses from a large number of geographic locations, including locations that do not make sense for the target business. For example, a US based retailer that has stores only in the US and only delivers in the US will not expect to receive large numbers of product searches from international, non-US based IP addresses. A handful of requests may be from US based customers that have travelled or who are using VPN services, but thousands of requests from unlikely geographic regions is indicative of automated scrapers.
Conversion or Look–to-Book Analysis
Typically, scrapers make lots of requests but never actually purchase anything. This negatively affects conversion rate business metrics. This also gives a way to identify these scrapers, by slicing and dicing the traffic similarly to traffic pattern analysis, but with emphasis on conversion rates within traffic segments. Entities that have high volume and zero conversions are typically scrapers that are only pulling data with no intention of converting. Examples of this are insurance quote comparison bots that request large numbers of quotes but never purchase. The same is true for competitor scrapers. They will conduct large numbers of searches and product page views but will not make any purchases.
Not Downloading or Fetching Images and Dependencies but Just Data
Users on Web will typically access a web page via their web browser which downloads all the web content and renders it. The content downloaded includes fonts, images, videos, text, icons etc. Efficient scrapers only request the data they are after and do not request any of the other content that is needed to render the page in a browser. This exclusion of content from their requests makes it possible to identify scrapers by looking for entities in the logs that are only requesting valuable pieces of data but not loading any of the associated content that is needed to successfully render the web page.
Behavior/Session Analysis
Website owners can analyze the behavior of incoming requests to identify patterns associated with web/API scraping, such as sequential or repetitive requests, unusual session durations, high page views, and fast clicks. A scraper might also bypass earlier portions of a normal user flow to go directly to a request, so if session analysis is seeing higher traffic volume at only certain points in a normal flow, that could also be a sign of scrapers. If your site has a search interface, checking those logs can also reveal scraper activities.
Unwanted scraper activity can also show up as higher than expected bounce rates. A bounce is defined as a session that triggers only a single request to the Analytics server, for example, if a user opens a single page or makes a single request and then quits without triggering any other requests during that session. Scraper activity tends to exhibit this behavior across large numbers of requests and sessions. Bounce rate is a calculation of the percentage of all transactions or requests that are categorized as bounces. Analyzing endpoints with above average bounce rates might reveal endpoints targeted by scrapers. Looking at clusters of traffic with high bounce rates can help identify unwanted scrapers.
Analysis of device behavior can be conducted using cookies and device/TLS fingerprints to identify sources of anomalous or high-volume requests that are indicative of scraper activity.
Account Analysis
Some websites require users to be authenticated in order to scrape the required data. For these sites, analysis of account names and email addresses used will help to identify scrapers and even sometimes identify the entity behind the scraping activity. Some entities like penetration testing companies and IP enforcement companies, tend to use their official corporate email domains to create the user accounts that are used for scraping. We have successfully used this method to attribute large numbers of unidentified scrapers.
You can also identify scrapers through the use of fake accounts. F5 Labs previously published an article describing 8 ways to identify fake accounts. The use of fake accounts is typical for scrapers that need to be authenticated. They cannot use a single account to conduct their scraping due to per account limits on requests, hence they create a large number of fake accounts and distribute the requests among a large number of accounts. Identifying fake accounts that primarily make data requests will unearth unidentified scraping activity.
How to Manage Scrapers
Management can include a spectrum of actions ranging from doing nothing, to rate limiting or access limiting, all the way to outright blocking. There are various methods that can be used to achieve scraper management with varying levels of efficacy, as well as different pros and cons. In this section we will cover some of the top methods used to manage scrapers and compare and contrast them so you can find the method best suited for your particular scraper use case.
Robots.txt
This is one of the oldest scraper management methods on the internet. This involves a file on your site that is named “robots.txt”. This file contains rules that site administrators would like bots (including scrapers) to adhere to. These rules include which bots or scrapers are allowed and those that are not. They include limits to what those scrapers are allowed to access and parts of the website that should be out of bounds. This robots.txt file and its rules have no enforcement power and rely on the etiquette of the scrapers to obey. Frequently scrapers simply ignore these rules and scrape the data they want either way. It is important therefore to have other scraper management techniques that can enforce the compliance of scrapers.
Site, App and API Design to Limit Data Provided to Bare Minimum
One effective approach to manage scrapers is to remove access to the data that they are after. This is not always possible in all cases as the provision of that data may be central to the enterprise’s business. However, there are cases where this is a plausible solution. By designing the website, mobile app and API to limit or remove the data that is exposed, this can effectively reduce unwanted scraping activity.
CAPTCHA/reCAPTCHA
CAPTCHAs (including reCAPTCHA and other tests) are another method used to manage and mitigate scrapers. Suspected scraper bots are presented with a challenge designed to prove whether they are real humans or not. Failing this CAPTCHA challenge will result in mitigation or other outcome designed for scrapers and bots. Passing the test would generally mean that the user is likely human and would be granted access the required data. CAPTCHA challenges pose a significant amount of friction to legitimate human users. Businesses have reported significant decreases in conversion rates when CAPTCHA is applied. As a result, many are weary of using it. Over the years with improvements in optical character recognition, computer vision and most recently multi-modal artificial intelligence (AI), scrapers and other bots have gotten even better than humans at solving these CAPTCHA challenges. This renders this method ineffective against more sophisticated and motivated scrapers while successfully addressing the less sophisticated ones.
Human click farms are also used to successfully solve CAPTCHA challenges for scrapers. These click farms are typically located in low-cost regions of the world and can solve CATPCHAs for cheap. These click farms have APIs that can be called programmatically with scrapers supplying the unique ID of the CAPTCHA they need to solve. The API will then respond with the token generated when the CAPTCHA has been successfully solved. This token will allow the scraper to bypass the CAPTCHA challenge. Figure 11 below shows an example of these click farms charging as little as $1 for 1000 solved CAPTCHAs.

Figure 11: CAPTCHA solving click farms
Honey Pot Links
Scrapers, unlike humans, do not look at the user interface of the website but rather look at the HTML and CSS code of the site. This means that they can see items on a web page that may be invisible to a real human user that is looking at the web page via a web browser. Security teams and web designers can therefore add invisible form fields and links onto a web page that only scrapers can see and interact with. This method allows the page to know when a given transaction is being performed by a scraper and respond accordingly. This response could be forwarding them to a honeypot, blocking the transaction or providing incomplete or misleading results.
Require All Users to be Authenticated
The vast majority of scraping occurs without authentication. This makes it harder to enforce access limits if you do not know who is requesting the data. A solution to this would be to require all users to be authenticated before they can make data requests. This will allow better control of how much data a given user can access. Most scrapers do not bother to go through the effort of creating an account and signing in unless forced to do so, hence such a measure might discourage some less motivated scrapers especially if they can get the same or similar data elsewhere without the same effort. However, for the more sophisticated and motivated scrapers, this becomes a different challenge. Those scrapers will resort to fake account creation. F5 Labs published an entire fake account creation bots article series covering this topic in great detail. These highly motivated and sophisticated scrapers will create large numbers of fake accounts and authenticate into them, then distribute their data request among these accounts such that they get the required data while sticking to any account level request limits.
The other issue is that requiring users to be authenticated will impose friction on users, potentially negatively impacting revenue. For example, if an airline decided that only authenticated users could search for flights, that would be detrimental to their ability to sell tickets as many users would be unwilling to create accounts just to search for flight information. As a result, this method is not feasible for a large number of businesses. However, for businesses that can implement this without negatively affecting their revenues, and have a way of mitigating the creation of large numbers of fake accounts, this might be a low-cost effective solution.
Cookie/Device Fingerprint Based Controls
In order to limit the number of requests a given user/device makes, there is a need to be able to distinguish between specific users/devices. Cookie based tracking or device/TLS fingerprinting can achieve this when requiring all users to be authenticated is not feasible. These methods are invisible to legitimate human users but allow site administrators to impose user/device level transaction limits. There are some challenges with this approach. For cookie-based approaches, it is trivial for scrapers to delete cookies after each request hence rendering any cookie-based transaction limits ineffective. Device fingerprinting has issues with collisions (different devices having the same fingerprint) and divisions (the same device having different or changing fingerprints) that also make any rate limits based on them less effective. Advanced scrapers using tools like Browser Automation Studio (BAS) and other modern frameworks have device fingerprint switching and anti-fingerprinting capabilities that also limit the effectiveness of this approach. Figure 12 shows a screenshot from the BAS website highlighting this capability.

Figure 12: BAS website highlighting browser fingerprint switching features
WAF Based Blocks and Rate Limits (UA and IP)
Web Application Firewalls (WAFs) can be used to manage scrapers. Rules based on user agent strings, headers and IP addresses can be created and rate limits can be established to limit how much data can be accessed by scrapers. These methods are effective only against the least sophisticated scrapers. Most advanced scrapers know to use common user agent strings like the latest versions of Chrome and Safari browsers that the WAF cannot mitigate on. They also know to use large numbers of IP addresses from the right geographic regions as well as common header orders. All these techniques make WAFs ineffective against sophisticated scraper bots.
Basic Bot Defense
Not all bot defense solutions are created equal. Basic bot defense solutions use simple JavaScript challenges, CAPTCHA challenges, device fingerprinting and user behavior analytics to identify scrapers. Basic bot defense solutions do not obfuscate their signals collection scripts, nor do they encrypt and tamper proof their signals collection. They also do not randomize or shuffle their signals collection code making it easier for sophisticated scrapers to reverse engineer. Some basic bot defense solutions will also use IP reputation and geo-blocking as a means of mitigating scrapers. These methods are effective against low to medium levels of sophistication scrapers. Basic bot defense solutions can be circumvented using a number of tools such as new generation automation tools like BAS and puppeteer that bypass all their detection techniques. The use of residential and other high quality proxy networks with high reputation IP addresses from the right geographic locations can also effectively bypass these solutions. Because the signals collection code is not obfuscated and does not get randomized in any way, it is easy for an advanced scraper to analyze the code to understand what is being collected and how. Then they just need to craft a spoofed signals packet that they know will fool the basic bot defense solution’s backend system, thereby effectively bypassing it.
Advanced Bot Defense
Advanced enterprise grade bot defense solutions use obfuscated signals collection that is randomized constantly to prevent reverse engineering. These solutions include tamper-protection on signals collection to enable the detection of any signals spoofing. Collected signals payloads are heavily encrypted to avoid tampering, as well as to prevent even advanced scrapers from knowing what is being collected and how. Many of the most advanced bot defense solutions also make use of machine learning (ML) and artificial intelligence (AI) to build robust and effective real time and offline detection and mitigation systems that ensure long term efficacy of scraper detections and mitigations.
These advanced bot defense solutions are the only effective defense against the sophisticated scrapers including those from AI companies. Their ability to adapt to varying automation techniques allow these solutions to provide effective defense against both identified and unidentified scrapers.
Scraper Management Methods/Controls Comparison and Evaluation
Table 3 below summarizes our evaluation of various scraper management methods and controls. It highlights the pros and cons of each approach and provides a rating score (out of 5) for each. The higher the score, the better and more effective the method or control against scrapers.
| Control | Pros | Cons | Rating |
| Robot.txt | + Cheap + Easy to implement + Effective against ethical bots |
- No enforcement - Ignored by most scrapers |
1 |
| Application redesign | + Cheap | - Not always feasible due to business need | 1.5 |
| CAPTCHA | + Cheap + Easy to implement |
- Not always feasible due to business need | 1.5 |
| Honey pot links | + Cheap + Easy to implement |
- Easily bypassed by more sophisticated scrapers | 1.5 |
| Require authentication | + Cheap + Easy to implement + Effective against less motivated scrapers |
- Not always feasible due to business need - Results in a fake account creation problem |
1.5 |
| Cookie/fingerprint based controls | + Cheaper than other solutions + Easier to implement + Effective against low sophistication scrapers |
- High risk of false positives from collisions - Ineffective against high to medium sophistication scrapers |
2 |
| Web Application Firewall | + Cheaper than other solutions + Effective against low to medium sophistication scrapers |
- High risk of false positives from UA, header or IP based rate limits - Ineffective against high to medium sophistication scrapers |
2.5 |
| Basic bot defense | + Effective against low to medium sophistication scrapers | - Relatively expensive - Ineffective against high sophistication scrapers - Poor long term efficacy - Complex to implement and manage |
3.5 |
| Advanced bot defense | + Effective against the most sophisticated scrapers + Long term efficacy |
- Expensive - Complex to implement and manage |
5 |
Conclusion
There are multiple ways to identify the various scrapers that target Web, Mobile and API application data. The methods differ depending on the kind of scraper and the kind of data they are targeting. Some scrapers are benign and identify themselves plainly. These include search engine crawlers, monitoring and penetration testing bots, as well as archival bots like the Wayback Machine. Other scrapers go to great lengths to conceal their activities. A number of different methods for identifying these scrapers were highlighted as well as ways of managing them. Different scraper management methods/controls have pros and cons; advanced bot defense solutions are the most effective against the entire spectrum of scraper sophistication, though they tend to be more expensive and complex to implement.







